


TL;DR
- An agent harness is the software layer that surrounds an AI model and manages tools, context, memory, execution, and results.
- Long-running agents need more than a large context window because tasks may continue across several sessions, environments, or model calls.
- Effective harnesses preserve progress through structured task lists, checkpoints, files, logs, and clearly defined handoffs.
- Agents should work on bounded tasks, verify each result, and leave the workspace in a usable state for the next session.
- Reliable execution requires failure recovery, permission controls, test environments, monitoring, and cost limits.
- Harness quality can affect agent performance as much as model selection.
What Is an Agent Harness?
An agent harness is the software layer that enables an AI model to operate as an agent. It manages the model’s instructions, context, tools, memory, execution loop, permissions, and outputs.
A model by itself can generate a response from the information available in its current context. A harness allows that model to interact with an environment, inspect results, call tools, update files, continue a workflow, and determine what to do next.
A typical agent harness handles:
- System instructions
- User objectives
- Context selection
- Tool definitions
- Tool execution
- State and memory
- Task planning
- Error recovery
- Permission checks
- Output validation
- Logging and monitoring
- Session handoffs
The model provides reasoning and language capability. The harness determines how that capability is connected to real tools and controlled during execution.
This distinction is important because an apparently capable model may still perform poorly when the surrounding harness provides weak context, unclear tools, no progress tracking, or inadequate verification.
Why Do Long-Running Agents Need a Harness?
A short agent task may fit within one model interaction. The agent receives a request, calls one or two tools, produces an answer, and stops.
Long-running AI agents work differently. They may need to:
- Complete dozens of connected tasks
- Continue across several context windows
- Operate for hours or days
- Resume after interruptions
- Use different environments
- Recover from tool failures
- Preserve decisions between sessions
- Verify work completed earlier
- Coordinate with other agents
A large context window alone does not solve these challenges. Continuously loading an entire history can increase cost, introduce irrelevant information, and make it harder for the model to identify the current task.
An effective harness converts an open-ended objective into manageable units of work. It records what has been completed, what remains, which decisions were made, and what the next session should do.
This creates continuity without forcing every session to reconstruct the full project history.
What Components Make an Agent Harness Reliable?
Task decomposition
The harness should divide a large objective into smaller tasks with clear completion conditions.
For example, an application-development agent should not receive only the instruction “build the product.” The harness may break the work into:
- Review requirements
- Set up the project
- Implement authentication
- Build the primary workflow
- Add validation
- Run tests
- Fix failures
- Prepare deployment
Each task should be narrow enough for the agent to complete and verify within a manageable context.
Persistent state
The harness must preserve important information outside the temporary model context.
Useful state may include:
- Task status
- Architecture decisions
- Files changed
- Test results
- Known issues
- Environment details
- Pending approvals
- Next recommended action
This information may be stored in structured files, databases, version control, logs, or dedicated state stores.
Context management
The harness should provide the information needed for the current task without including the full execution history.
Relevant context may include:
- Current objective
- Active task
- Recent decisions
- Required files
- Tool results
- Applicable constraints
- Previous errors
Context should be selected intentionally. More context is not automatically better context.
Tool orchestration
The harness controls which tools the agent can use and how they are presented.
Tools may include:
- File operations
- Code execution
- Search
- Browsers
- Databases
- APIs
- Testing systems
- Version control
- Deployment platforms
Each tool should have a clear purpose, validated parameters, limited permissions, and understandable results.
Verification
The harness needs a method for determining whether a task is actually complete.
Verification may involve:
- Automated tests
- Schema validation
- File checks
- API responses
- Browser tests
- Static analysis
- Human approval
- Comparison with acceptance criteria
Without verification, an agent may mark a task complete because the output appears plausible rather than because it works.
Recovery and retries
Tools fail, APIs time out, tests break, and environments change. The harness should distinguish between recoverable failures and problems requiring escalation.
A reliable recovery process defines:
- Which actions may be retried
- How many retries are allowed
- Whether a different approach should be attempted
- What information should be preserved
- When human review is required
How Does Anthropic Harness Design Support Long-Running Work?
Anthropic’s harness design for long-running application development uses a structured separation between initialization and continued execution.
An initializer can interpret the overall specification, prepare the environment, and convert the project into a persistent task list. Later agent sessions can select one task, inspect the current project state, complete the work, verify it, and update the shared artifacts.
A simplified flow is:
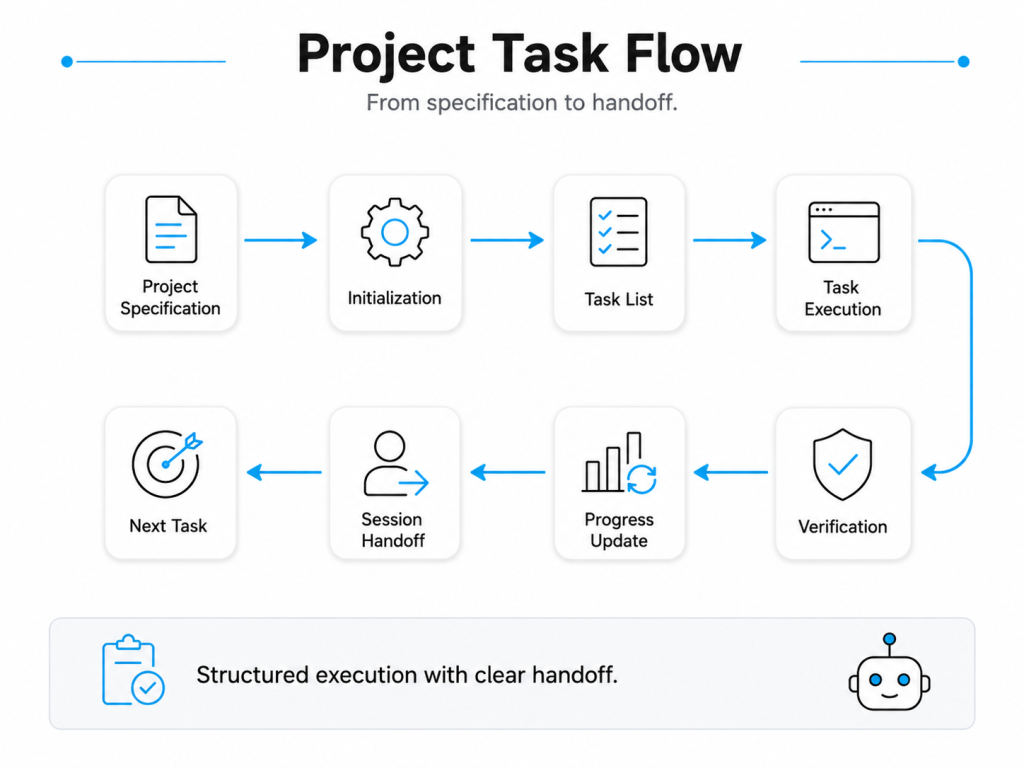
This pattern addresses a major limitation of long-running agents: the next context window does not automatically understand everything that occurred in the previous one.
The harness creates continuity through external artifacts rather than depending only on conversational memory.
Teams should also understand the broader structure of agentic workflows because harness design determines how planning, tool use, validation, and escalation operate across each workflow stage.
How Should Progress Continue Across Sessions?
Each session should begin by reconstructing only the information required to continue safely.
A useful startup process includes:
- Read the primary objective
- Inspect the task list
- Review recent progress notes
- Check the working environment
- Run relevant tests
- Select one incomplete task
- Complete and verify that task
- Update the task status
- Record the next recommended action
The previous session should leave the workspace in a stable condition. Files should be saved, changes should be traceable, and broken experiments should not be left without explanation.
Example handoff record
A structured handoff may contain:
- Completed: Added authentication endpoints
- Files changed: auth.py, routes.py, test_auth.py
- Verification: Authentication tests passed
- Known issue: Password-reset email not configured
- Next task: Implement password-reset workflow
- Do not change: Existing token-expiration logic
This is more reliable than asking the next session to infer progress from a long conversation history.
How Is an Agent Harness Different From an Agent Framework?
An agent framework provides reusable components for creating agents. It may include tool interfaces, workflow graphs, memory modules, model integrations, and orchestration utilities.
An agent harness is the configured operating system around a specific agent or workflow.
| Area | Agent framework | Agent harness |
| Primary purpose | Provides development components | Controls agent execution |
| Scope | General-purpose library or platform | Specific workflow or application |
| Context | Offers context features | Selects and manages actual context |
| Tools | Defines tool interfaces | Controls approved tools and permissions |
| State | Provides storage options | Determines what state is preserved |
| Evaluation | May include testing features | Enforces task-specific verification |
| Recovery | Offers technical mechanisms | Defines workflow recovery behaviour |
| Governance | Usually implementation-dependent | Applies actual limits and approvals |
A team may use a framework to build its harness, but installing a framework does not automatically create a reliable, long-running agent.
Reviewing the different types of AI agents can help teams determine whether the harness needs simple routing, goal-based planning, utility-based selection, learning, or multi-agent coordination.
How Can You Build an Effective Harness for Long-Running Agents?
1. Define a measurable objective
Replace broad instructions with an outcome that includes constraints and completion criteria.
2. Break the objective into bounded tasks
Each task should be small enough to execute and verify without loading the full project.
3. Create a persistent source of truth
Store tasks, decisions, issues, test results, and progress outside the model context.
4. Control context deliberately
Provide the files, history, decisions, and tool results relevant to the active task.
5. Restrict tools and permissions
Give the agent only the tools and access required for its assigned work. Separate read, write, execution, and deployment permissions.
6. Require verification before completion
A task should not be marked complete until its acceptance criteria have been checked.
7. Design explicit handoffs
Every session should record what changed, how it was tested, what remains, and what should happen next.
8. Add failure and cost limits
Limit retries, model calls, execution time, tool usage, and infrastructure consumption.
9. Monitor real execution
Track task completion, errors, retries, context size, tool failures, token usage, and human intervention.
10. Expand autonomy gradually
Begin in a sandbox or controlled environment. Increase access only after the harness performs reliably under normal and failure conditions.
The AI agent security principles of least privilege, tool validation, auditability, and approval controls become especially important when agents operate for long periods or across production systems.
Design a Reliable Harness for Your AI Agent
Discuss your long-running workflow, context management, tool integrations, state persistence, verification, security, and deployment requirements with our AI agent development team.

What Common Harness Design Mistakes Should You Avoid?
One large instruction for the entire project
Broad prompts give the agent no reliable way to prioritize, measure progress, or determine completion.
Using chat history as the only memory
Conversation history is difficult to validate, expensive to reload, and poorly structured for operational state.
Marking tasks complete without verification
Generated output may appear correct while tests, integrations, or requirements remain incomplete.
Giving every tool at once
Large toolsets increase context use and make incorrect tool selection more likely.
Allowing endless retries
An agent may repeatedly attempt the same failed action while consuming tokens and infrastructure.
Weak session handoffs
The next session may repeat completed work, undo decisions, or overlook unresolved failures.
Changing models without regression tests
Harness behaviour depends on the model and the surrounding system together. A model change can alter tool selection, planning, and error handling.
How Should Harness Performance Be Measured?
Do not measure a long-running agent only by whether it eventually produces an output.
Track:
| Measurement area | Useful metric |
| Task progress | Verified tasks completed |
| Reliability | Successful completion rate |
| Recovery | Failures resolved without manual restart |
| Verification | Tests passed before completion |
| Efficiency | Tokens and tool calls per task |
| Continuity | Successful session handoffs |
| Quality | Human corrections and reopened tasks |
| Safety | Unauthorized or blocked actions |
| Cost | Model, tool, and infrastructure expense |
| Intervention | Human reviews and escalations |
The most useful metric is verified forward progress. An agent that stays active for hours without completing validated work is not operating effectively.
Frequently Asked Questions
What is an agent harness?
An agent harness is the software layer surrounding an AI model that manages instructions, context, memory, tools, execution, permissions, validation, and results.
Why do long-running agents need a harness?
Long-running tasks may exceed one context window or session. A harness preserves progress, selects relevant context, manages tools, handles failures, and enables the next session to continue reliably.
Is an agent harness the same as an AI agent framework?
No. A framework provides reusable development components. A harness is the specific execution structure that controls how an agent operates within a workflow.
What makes an agent harness effective?
An effective harness uses bounded tasks, persistent state, deliberate context selection, restricted tools, verification, failure recovery, monitoring, and clear session handoffs.
What is Anthropic’s harness engineering?
Anthropic harness engineering refers to designing the systems around AI models so agents can complete extended work reliably. Important elements include task decomposition, persistent artifacts, context handoffs, verification, and controlled execution.
Can a larger context window replace an agent harness?
No. A larger context window can hold more information, but it does not independently provide task tracking, tool control, verification, recovery, permissions, or structured session handoffs.
How should an agent preserve progress?
Store progress in external artifacts such as task lists, files, databases, version control, test reports, and structured handoff notes instead of relying only on conversational memory.
When should a business use a long-running AI agent?
Use one when a valuable task requires several connected steps, tools, sessions, or environments. Simpler workflows may be more reliable and economical with fixed automation or shorter agent runs.








 30 mins free Consulting
30 mins free Consulting 
 12 min read
12 min read 







 Love we get from the world
Love we get from the world 